转载自知乎回答:程序喵大人 https://www.zhihu.com/question/441518636/answer/1701252133
if-else涉及到分支预测的概念。
首先看一段经典的代码,并统计它的执行时间:
1 | // test_predict.cc |
此程序的执行时间是7.9秒,如果把排序那一行代码注释掉,即
1 | // std::sort(data, data + ARRAY_SIZE); |
结果为:
1 | ~/test$ g++ test_predict.cc ;./a.out |
改动后的程序执行时间变为了24秒。
其实只改动了一行代码,程序执行时间却有3倍的差距,而且看上去数组是否排序与程序执行速度貌似没什么关系,这里面其实涉及到CPU分支预测的知识点。
提到分支预测,首先要介绍一个概念:流水线。
拿理发举例,小理发店一般都是一个人工作,一个人洗剪吹一肩挑,而大理发店分工明确,洗剪吹都有特定的员工,第一个人在剪发的时候,第二个人就可以洗头了,第一个人剪发结束吹头发的时候,第二个人可以去剪发,第三个人就可以去洗头了,极大的提高了效率。



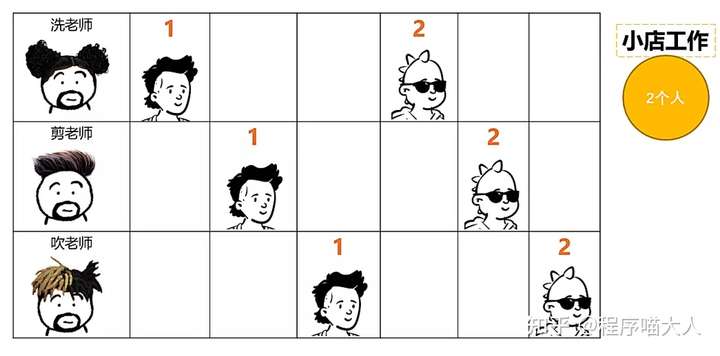
这里的洗剪吹就相当于是三级流水线,在CPU架构中也有流水线的概念,如图:
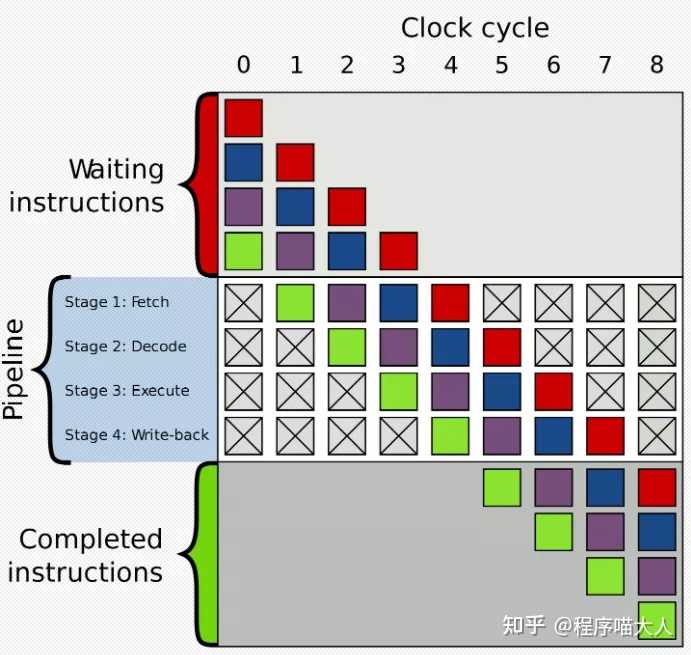
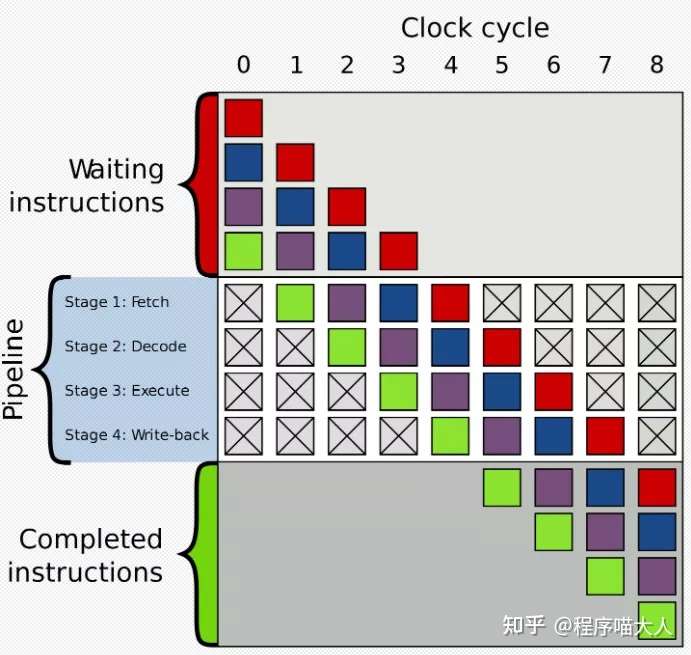
在执行指令的时候一般有以下几个过程:
- 取指:Fetch
- 译指:Decode
- 执行:execute
- 回写:Write-back
流水线架构可以更好的压榨流水线上的四个员工,让他们不停的工作,使指令执行的效率更高。
再谈分支预测,举个经典的例子:
火车高速行驶的过程中遇到前方有个岔路口,假设火车内没有任何通讯手段,那火车就需要在岔路口前停下,下车询问别人应该选择哪条路走,弄清楚路线后后再重新启动火车继续行驶。高速行驶的火车慢速停下,再重新启动后加速,可以想象这个过程浪费了多少时间。
有个办法,火车在遇到岔路口前可以猜一条路线,到路口时直接选择这条路行驶,如果经过多个岔路口,每次做出选择时都能选择正确的路口行驶,这样火车一路上都不需要减速,速度自然非常快。但如果火车开过头才发现走错路了,就需要倒车回到岔路口,选择正确的路口继续行驶,速度自然下降很多。所以预测的成功率非常重要,因为预测失败的代价较高,预测成功则一帆风顺。
计算机的分支预测就如同火车行驶中遇到了岔路口,预测成功则程序的执行效率大幅提高,预测失败程序的执行效率则大幅下降。


图片取自下方参考资料中
CPU都是多级流水线架构运行,如果分支预测成功,很多指令都提前进入流水线流程中,则流水线中指令运行的非常顺畅,而如果分支预测失败,则需要清空流水线中的那些预测出来的指令,重新加载正确的指令到流水线中执行,然而现代CPU的流水线级数非常长,分支预测失败会损失10-20个左右的时钟周期,因此对于复杂的流水线,好的分支预测方法非常重要。
预测方法主要分为静态分支预测和动态分支预测:
静态分支预测:听名字就知道,该策略不依赖执行环境,编译器在编译时就已经对各个分支做好了预测。
动态分支预测:即运行时预测,CPU会根据分支被选择的历史纪录进行预测,如果最近多次都走了这个路口,那CPU做出预测时会优先考虑这个路口。
tips:这里只是简单的介绍了分支预测的方法,更多的分支预测方法资料大家可关注公众号回复分支预测关键字领取。
了解了分支预测的概念,我们回到最开始的问题,为什么同一个程序,排序和不排序的执行速度相差那么多。
因为程序中有个if条件判断,对于不排序的程序,数据散乱分布,CPU进行分支预测比较困难,预测失败的频率较高,每次失败都会浪费10-20个时钟周期,影响程序运行的效率。而对于排序后的数据,CPU根据历史记录比较好判断即将走哪个分支,大概前一半的数据都不会进入if分支,后一半的数据都会进入if分支,预测的成功率非常高,所以程序运行速度很快。
如何解决此问题?总体思路肯定是在程序中尽量减少分支的判断,方法肯定是具体问题具体分析了,对于该示例程序,这里提供两个思路削减if分支。
方法一:使用位操作:
1 | int t = (data[c] - 128) >> 31; |
方法二:使用表结构:
1 |
|
其实Linux中有一些工具可以检测出分支预测成功的次数,有valgrind和perf,使用方式如图:
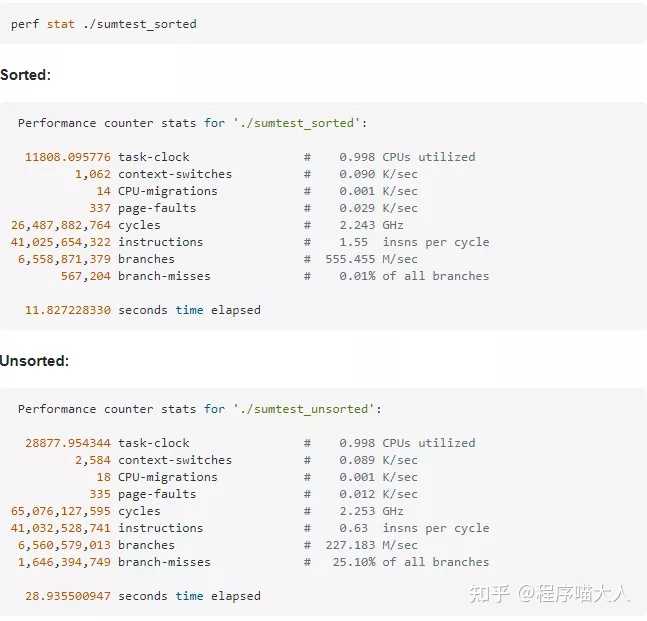
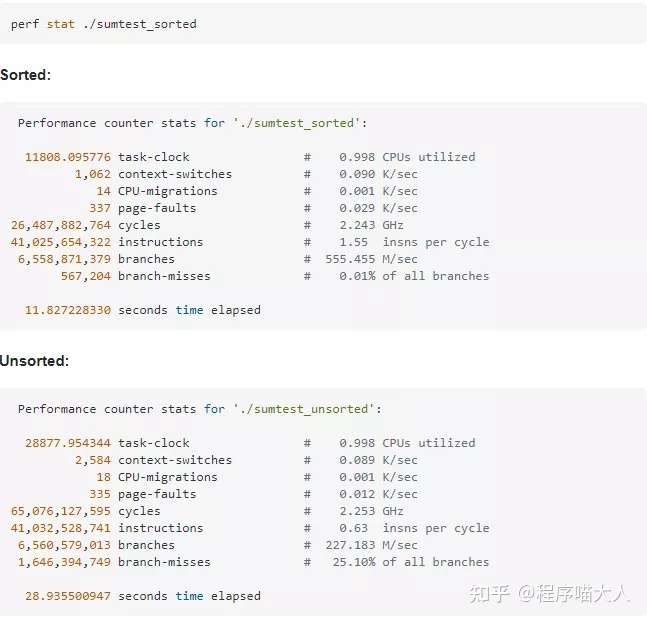
条件分支的使用会影响程序执行的效率,我们平时开发过程中应该尽可能减少在程序中随意使用过多的分支,能避免则避免。
